In May 2020 we presented a virtual fireside chat at the Open Publishing Fest called “Data Science as an Entryway to Open Publishing”. The premise was that the open source R programming language is a powerhouse for data analysis and statistics – and it also is fueling open publishing through R Markdown and a large, engaged, and innovative community. We briefly showed community-created examples of tutorials, blogs, websites, manuscripts, books, etc, and discussed how they are an entryway to open science, preprints, and open scientific publishing. This post is some reflections from the experience and summary of our slides.
One of the (many) things that gets us excited about R is that the same workflow you use for data analysis – that is rooted in reproducibility – empowers you make your work available to the world…in ways you never imagined.
As Julia said in our presentation:
“I came to R for the data analysis, and was blown away by the publishing.”

We then introduced R Markdown, framed for scientific publishing and so much more.
Using R Markdown for scientific publishing
R Markdown
R Markdown powerfully combines executable R code with simple text formatting for efficient, automatable, reproducible research. It combines simple text formatting with R code, which means analyses and figures are in the same place as your reporting document. This saves time as you iterate, and enables good practices for reproducibility & versioning.
R Markdown’s familiar outputs for science
R Markdown renders to Word and PDF — imagine never copy-pasting a graph into your report again!!! R Markdown can also manage citations, cross-referencing figures and section headers.

But wait, you can also use R Markdown behind your wildest dreams.
Using R Markdown beyond your wildest dreams
Using R Markdown also enables things you may not have thought you could create. It allows you to reimagine sharing and publishing online.
Create HTML files that can be shared openly on the web
We can render R Markdown to HTML. And we can store and distribute HTML files on GitHub, which also offers display options for publishing. Suddenly you can share a URL rather than attaching a file — and that same URL will update rather than re-attaching a new version of the file!
We shared some real-world examples from science, including examples from:
The Ocean Health Index,
Ben Marwick’s PhD thesis template formatting for the University of Washington,
These examples started with single-page HTMLs, with the ability to display floating table of contents and toggle between showing hiding code. And also simple websites that combine R Markdown files as a website with a navigation bar between pages, and requires only GitHub to display.
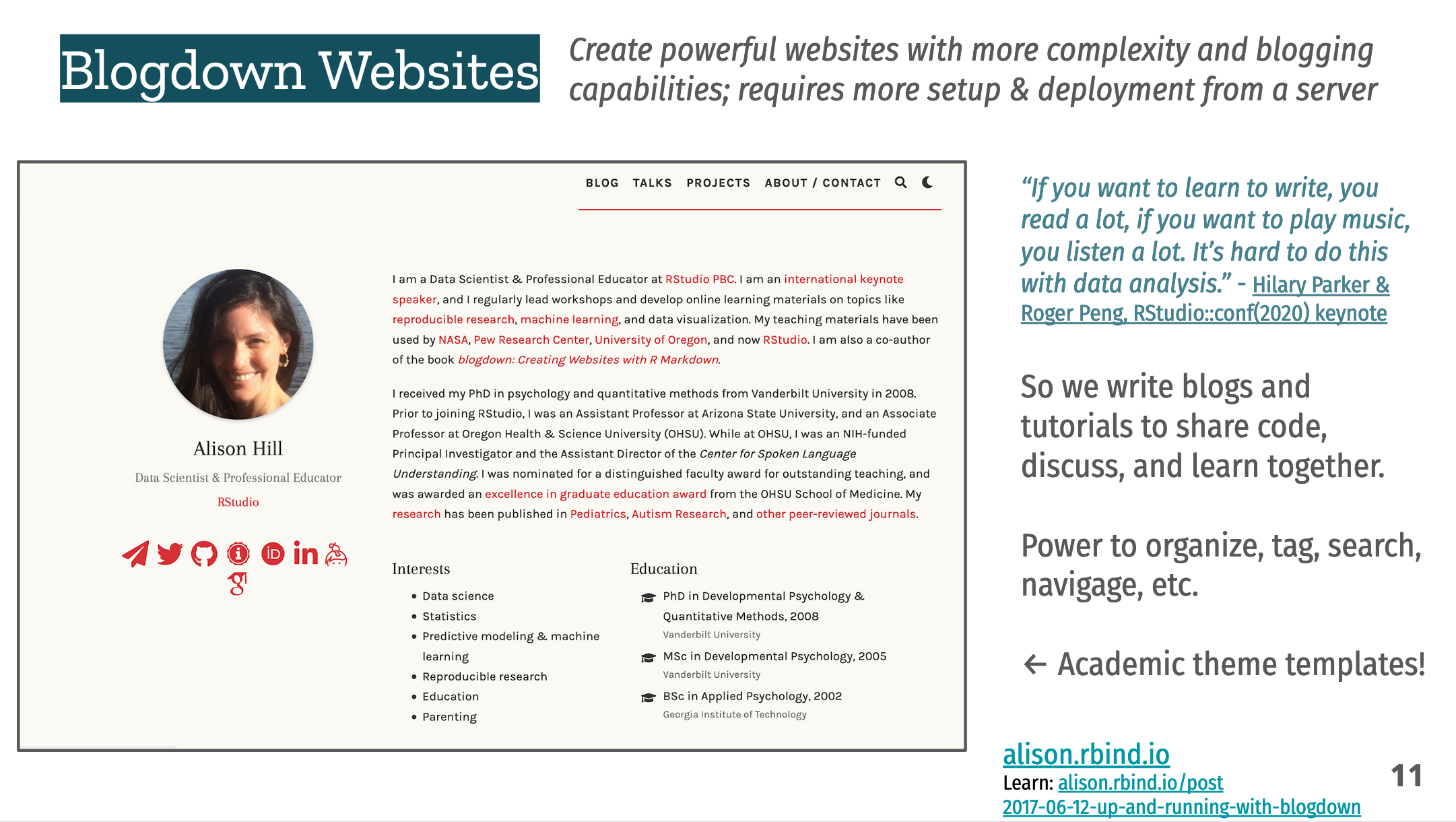
We also discussed blogdown that creates powerful websites with more complexity and blogging capabilities. This has been so important for creating blogs and tutorials to share code, discuss, and learn together. Why this important is nicely represented in this quote from the 2020 RStudio conference:
“If you want to learn to write, you read a lot, if you want to play music, you listen a lot. It’s hard to do this with data analysis.” — Hilary Parker & Roger Peng, RStudio::conf(2020) keynote
In addition to websites, R Markdown can create bookdown books that organize and navigate html files as e-books. This is really powerful for organizing reports and documents.
We can also create simple slides from a single R Markdown file – imagine making a presentation and then being able to re-create presentations with updated data! Further, we can create xaringan slides that enable you to incorporate powerful styling options from within R (without requiring knowledge of JavaScript, CSS, etc).
learnr provides the power of interactive tutorials from a friendly website interface. This is really exciting to think about reimagining teaching and how to blend lectures and hands-on coding for learners of all levels.
Discussion time
After going through the slides, we discussed with attendees the benefits of a HTML-focussed workflow. One of the benefits of this is that by avoiding page breaks, all your figures and tables can usually be placed right where they are mentioned. Although this might seem like a small detail, avoiding page breaks actually saved you a huge amount of time and hassle. Adam Sparks discussed that one of the benefits to HTML is the ease of sharing these in a team internally - they do not have to be published online, and can be opened in any browser. The fact that they often look really snappy and polished, and can include interactive elements like maps is also a huge selling point.
We also discussed how pagedown provides a fresh approach to generating PDFs on the web, and were lucky to have the creator of paged.js (which powers pagedown) Adam Hyde at our chat.
We also discussed some alternative formats for publishing, such as JATS, a journal publishing standard for XML. We hadn’t heard of it, (and apparently that was a good thing).
Alison Hill made an excellent point:
“As a former scientist, I felt woefully ill-equipped when first working with HTML output. I know you all have thought a lot about this- how can we increase HTML comfort levels and fluency for new/early scientists?”
In response to this we discussed some of the downfalls of HTML, namely the fact that CSS is usually required to answer questions like:
- “How do I change the font size”
- “How do I change the font colour”, or
- “How do I create two columns of text”
While CSS is ubiquitous, and everywhere on the web, so it can be easy to change appearances of text. It is an additional learning point for learners, and something that can tip the balance and turn people away and back to systems they know.
Some suggestions on addressing this were:
- Showing students existing R Markdown HTML templates
- Providing simple CSS templates within an R Markdown file for people to use
- Building better tools that guide people to create their own CSS
We had another interesting question from John Chodacki:
“What about readers/consumers? But it seems like all the cool features of auto-updating tables, etc. can bring confusion for the reader … unable to rely on stable info. Do you agree? Are there innovative ways to mitigate?”
This problem can arise when you generate a graphic, or a model during data analysis, and iterate on it and improve it. Later one, you might want to compare your current graphic to your first one, or your first model to the current one. However, doing that is actually pretty hard, and involves some strong version control skills. We discussed an approach that Miles McBain broached a few years ago called journalr (repo).
Ultimately, this is a hard problem to solve, and mimics a real life pen and paper notebook. Roger Peng discussed an approach to this in the NSSDeviations podcast (we believe in Episode 74), involving a manual approach.
